Computational Physics (Part2)【未完结】
Computational Physics (Part2)
[TOC]
5. Roots and Extermal Points
5.1 Root Finding
If there is exactly one root in the interval
5.1.1 Bisection
Basic idea: Use dichotomies to find change intervals
Remark: It converges but only slowly since each step reduces the uncertainty by a factor of 2
5.1.2 Regula Falsi (False Position) Method
Basic idea: use the polynomial interpolation to help find the root, and the rest is the same of bisection
If
the root of this polynomial is given by
5.1.3 Newton-Raphson Method
Basic idea: First/Second order Taylor expansion approximation
the first order Newton-Raphson method
the second order Newton-Raphson method
Remark: The Newton-Raphson method converges fast if the starting point is close enough to the root. Analytic derivatives are needed. It may fail if two or more roots are close by.
5.1.4 Secant Method
Basic idea:
6. Monte Carlo Method
Mathematical foundations:
- Law of large numbers
- Central limit theory
6.1 Pseudo-random Number
6.1.1 Linear Congruential Generator
In order to make the period of the linear congruence generator as large as possible, the three following conditions should be satisfied:
and are mutual prime , where p is any prime factor of m , if m is divisible by 4
Marsaglia effect:
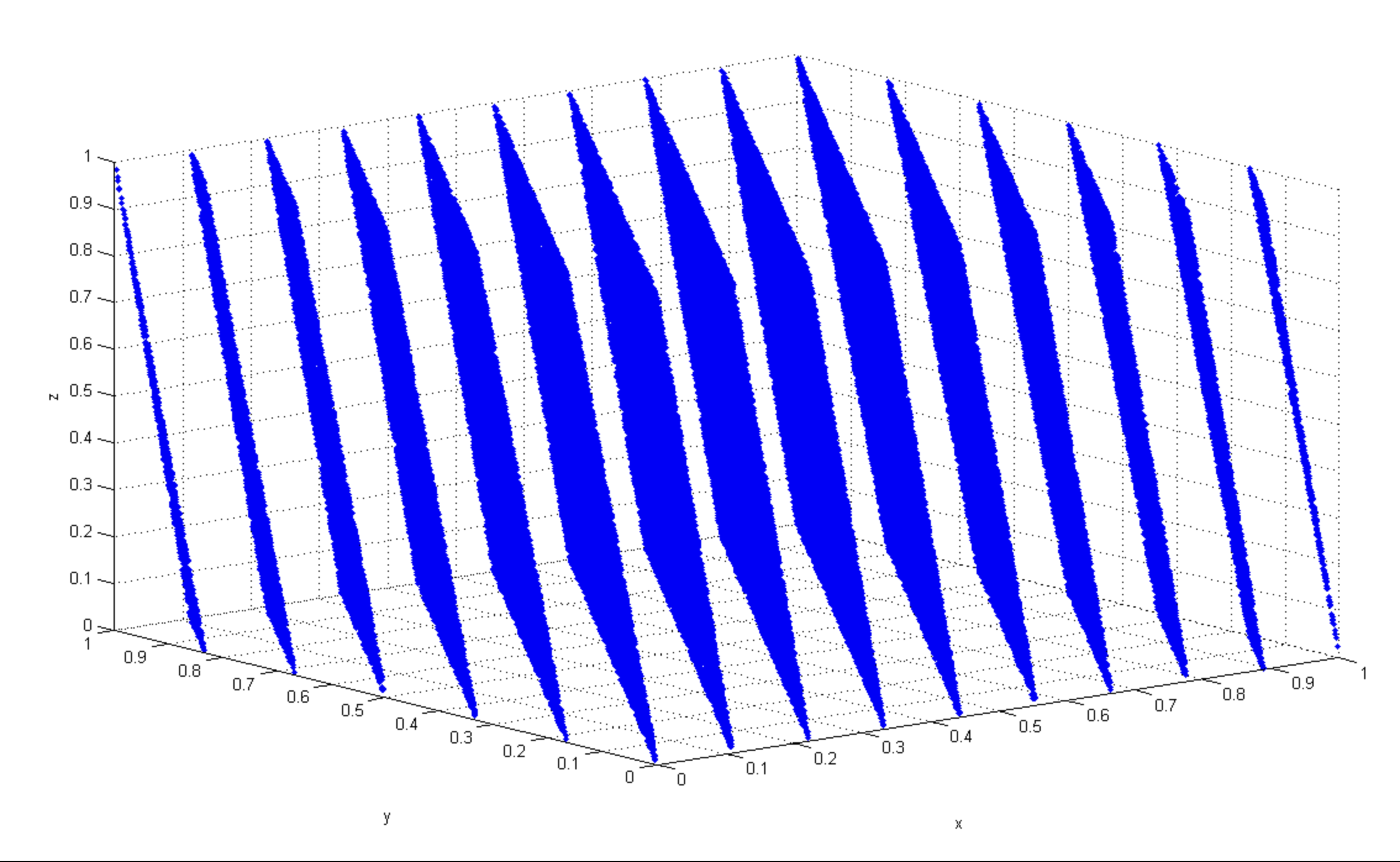
Define the points
on a unit
6.1.2 Mersenne Twister
Basic idea:
The generator maintains a state of 624 integers, each 32 bits in size, which is referred to as the state vector. The core idea behind the “twisting” is the application of a transformation function to the state vector.
The state undergoes a series of bitwise operations (such as XOR and shifting) to combine the current state into a new value.
Once the state is initialized, the Mersenne Twister generates pseudorandom numbers by extracting bits from the state vector. These numbers are generated sequentially, and the state vector is updated after each number is produced using the twisting transformation.
6.2 Monte Carlo Method
6.2.1 Direct Sampling
6.2.1.1 Continuous Variable
Basic idea: the random number of the distribution we want is generated by a given function transformation.
If we regard
Box-Muller Method:
6.2.1.2 Discrete Variable
Method 1: use two unitary random variables
Method 2: use only one random variable
6.2.2 Importance Sampling
Motivation:
We want to use Monte Carlo to compute
Basic idea: Avoid the situation mentioned above by changing the probability distribution of the sample by transforming it. Thus, the variance of statistical results is reduced.
we focus on computing
The idea of importance sampling is to rewrite the mean as follows. Let
We can write the last expression as
Note that we assumed that
Advangtage:
Let
Since we do not know
6.2.3 Reweighting and Correlation Sampling
Basic idea: The idea of reweighting gives rise to the concept of what is called relational sampling, which is calculating the average of two different physical quantities using a set of distributions.
When we sample the distribution
where
The proof is straightforward:
Remark:
The requirement of this method is that the weights should be as close as possible, otherwise the convergence of the calculation will become worse; To some extent this is similar to the understanding in importance sampling.
6.3 Markov Chain Monte Carlo Method
Motivation: How to sample a correlated multidimensional distribution?
Basic idea:
A Markov chain is a sequence of random variables where the next state depends only on the current state (not on previous ones). This “memoryless” property is key to MCMC, as it allows us to generate samples step by step based on the current state.
Starting from an initial state, the algorithm generates a sequence of states by applying a transition function that is designed so that, in the long run, the sequence of states will approximate the target distribution.
Key Steps in MCMC:
- Initialization: Start at a random state.
- Sampling: Propose a new state based on the current state.
- Acceptance: Accept the new state with a probability that ensures convergence to the target distribution.
- Repeat: Continue the process for many iterations to generate a sequence of samples.
we can get the possibility distribution of
6.3.1 Detailed Balance
Motivation: Whether
When we reach the balance:
If
which we call it detailed balance condition,
6.3.2 Convergence to Stationarity
need to be completed
6.3.3 Metropolis-Hastings Algorithm
Basic idea: We decompose conditional probability into two subprocesses ——Test first, then choose whether to accept
In the Metropolis-Hastings algorithm, in fact, the probability of receiving can be expressed as follows
This approach can avoid cases where the probability distribution is very steep, and the algorithm will not always reject it, thus increasing the convergence speed.
The Metropolis-Hastings algorithm satisfies the condition of detailed balance.
Convergence to stationarity
We consider that the contribution of
If
use the detailed balance and normalizing condition, we finally get
Usually we take
6.4 Statistical Error Analysis
6.4.1 Average Values and Statistical Errors
6.4.2 Blocking Analysis
Motivation: In Monte Carlo simulations or other random processes, the sampled data often have a certain degree of autocorrelation, that is, the value of one sample may have some correlation with the value of the previous sample. This affects the estimate of the sample mean and error, as using all the data directly may underestimate the error. Block analysis reduces the effect of autocorrelation by splitting the data into multiple smaller blocks, resulting in more reliable error estimates.
Consider a list of samples, each given the value
then we calculate the average of
Finally we get the standard deviation
6.4.3 Bootstrap Method
Basic idea: The distribution of sample statistics (such as mean, variance, etc.) is estimated by repeated sampling to derive error estimates and confidence intervals.
Repeat random sampling in the original sample
and then
and
6.4.4 Jackknife Method
Basic idea: The core idea of the Jackknife method is to estimate the bias and variance of the statistics by removing one sample point at a time and calculating the statistics based on the remaining samples.
6.5 Monte Carlo Simulation Example
6.5.1 Two-dimension Ising Model
Basic idea: need to be completed
6.5.1.1 General Condition
the total acceptance possibility is
where
With the above Monte Carlo basic operation, we can count the physical quantities we are interested in, such as
We use the self-correlation function to see how much length we need to take to do the Monte Carlo simulation is appropriate
usually we assume that the self-correlation function has an exponential decay from
the fitting parameter
In addition to fitting the exponential function, it is actually possible to integrate the correlation function whose integral also converges to the correlation time
In practice, we usually calculate
and it’s discrete form is
or we can calculate with the help of Fourier transformation
Additionally, we can easily show that the correlation time corresponds to the eigenvalue of the Markov matrix
Except the self-correlation function, we can also define so-called two-body correlation function
which we can calculate by the following form
or the Fourier transformation method
6.5.1.2 Monte Carlo Simulation Near Critical Temperature
Basic idea: Clustering flipping algorithm, Flipping too slowly one by one, flipping a large number of related grid points at a time, is called a cluster
How to define a cluster?
Key point: First randomly select a point, and then extend the connection outward, the connection probability satisfies
The reason why we take
where the process from
Therefore, we can take
We can avoid talking about the acceptance probability.
- Swendsen-Wang Algorithm
All clusters flip simultaneously with a probability of 1/2
- Wolff Algorithm
Only one cluster is found at a time, and this cluster must be flipped
6.5.2 Spatial Distribution of Particles
Basic idea: the final equvilibrium distribution is given by the partition function, and the use the Metropolis method
6.5.2.1 Canonical Ensemble
If we want to know the statistic properties of a group of particles
and
using the Metropolis method to sampling, we can define the acception possibility
which means when the total potential decreases, we must accept this transition.
In each step, we just move one particle with an appropriate step length which leads to about 50% accept possibility (since we move all particles will induce a vary large change of potential, leading to a vary low accept possibility)
6.5.2.2 Volume is Not Fixed
If the volume is not fixed, we can rewrite the partition function
then
acceptance possibility
6.5.2.3 Grand Canonical Ensemble
Then we have
6.5.3 Solve Differential Equation by Monte Carlo Method
Basic idea: need to be completed
Advantage: The statistical error decreases with the increase of the number of Monte Carlo samples and does not depend on the dimension of the space.
6.5.3.1 Walk on Spheres Method
Basic idea: the solution inside the region relates to that on boundary.
Consider an arbitary dimension Laplace’s equation
An important relation is
(the institutive interpretation of this relation is the balance of a diffusion process)
The symbol
What about a random process —— Walk on Spheres
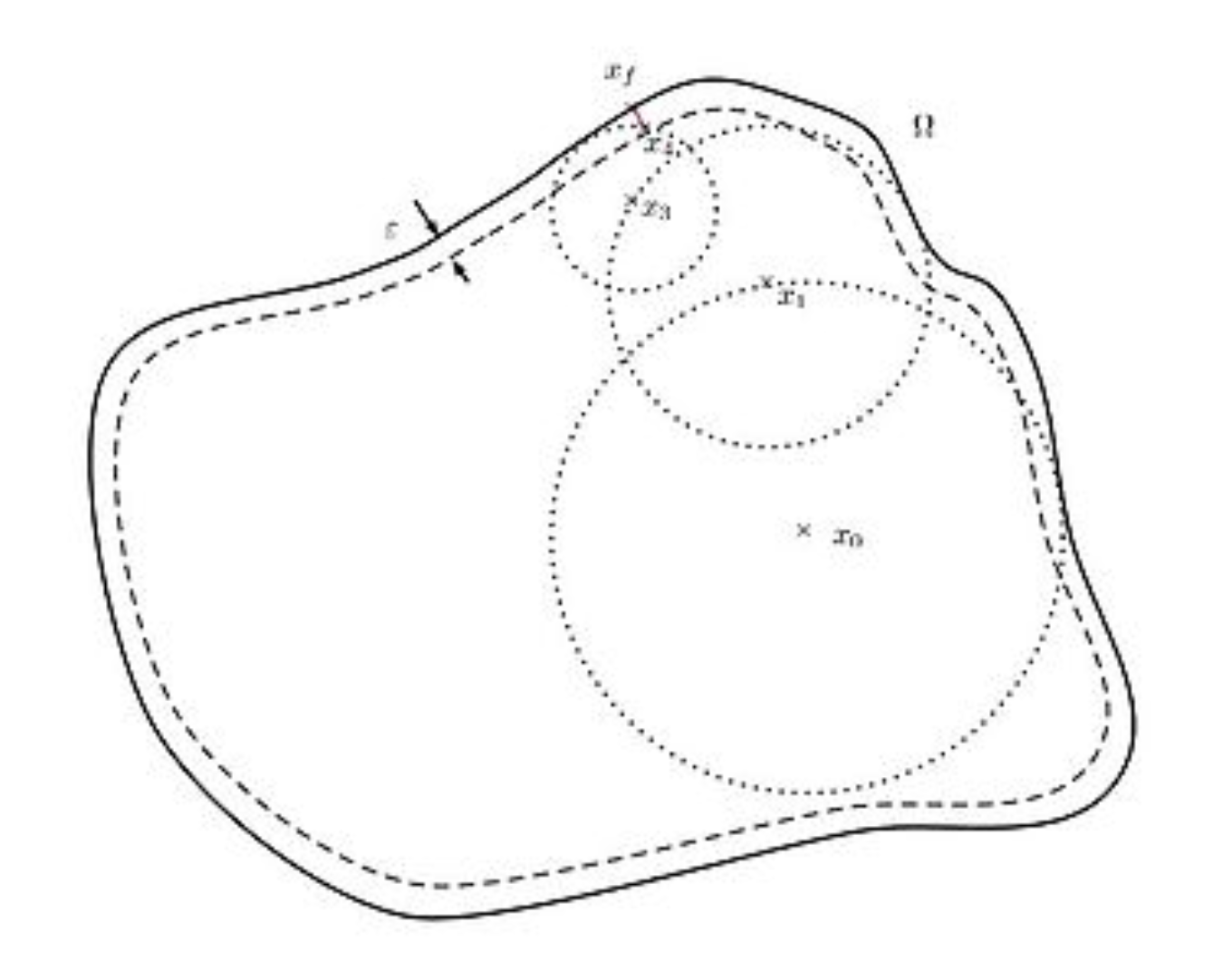
the dash line in the picture denotes the cut-off region.
6.5.3.2 Green’s Function Method
Basic idea: treat all 𝑓 as a set of many point sources whose potential field 𝑢 is the integral of its product with its Green’s function. The specific operation is modeled after the previous discussion, that is, a random point source is generated according to the distribution of
Another method to cut-off ——Green’s function first passage
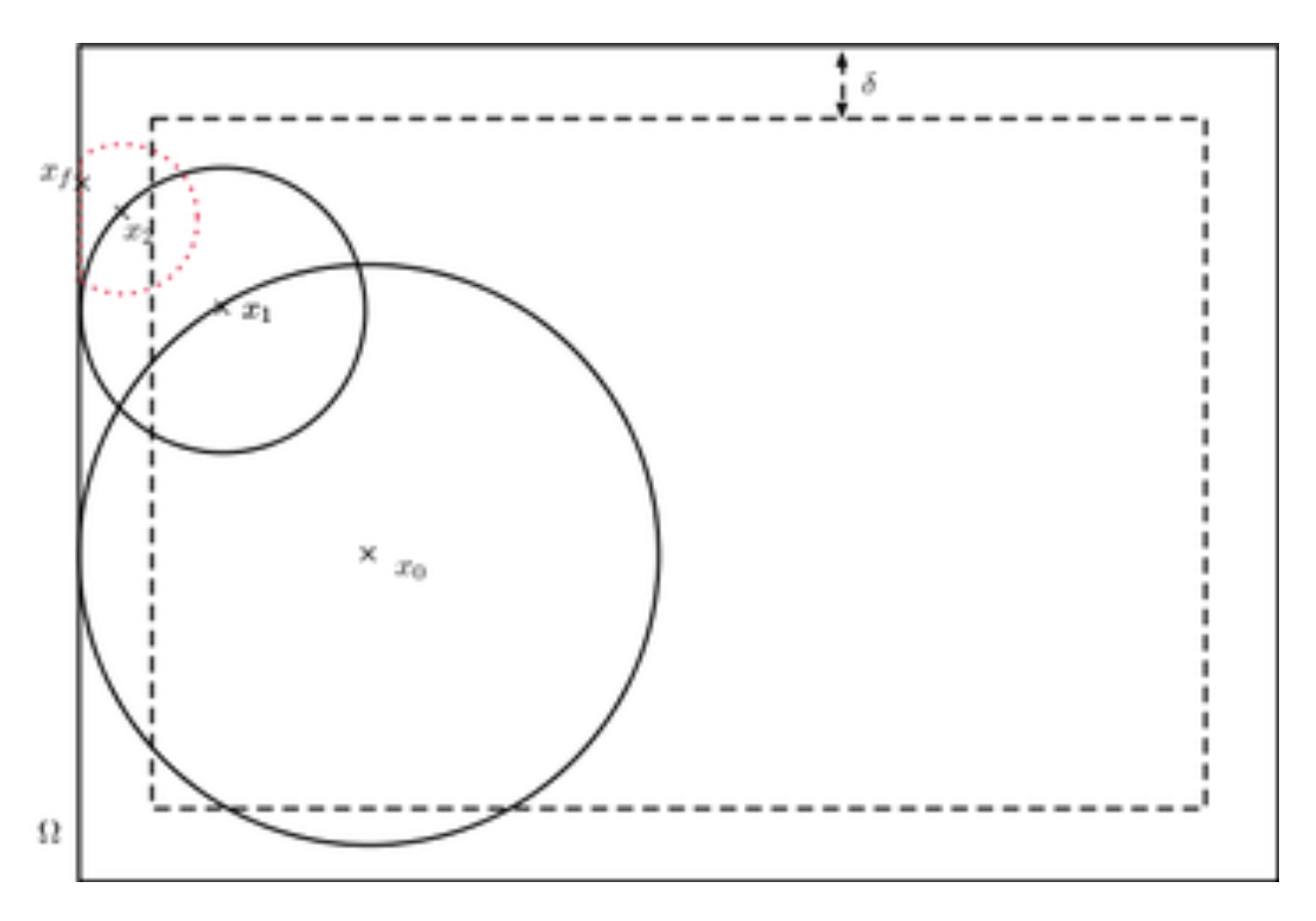
the radius of the red sphere is
Now let’s consider a general differential equation
the Green’s function satisfies
and the solution is
Considering the first coundary condition, the solution can be wriiten as
The so-called Green function first channel method is actually a process that requires a special Green function under given boundary conditions and then uses it to sample.
6.5.3.3 Initial-value Problem
the Green’s function is given by
the solution is
We can regard this relation as an implicit recursion
We can define
6.5.4 Quantum Mento Carlo
Basic idea: Shrodinger equation is also a differential equation
Naturally, we can choose sampling distribution
then
where
the integral can be discrete
Then, how do we optimize the wave function. Note that in the variation principle, we have
Suppose the wave function can be described by a parameter
Our goal is to find a appropriate
But how to ansatz the form of
6.5.4.2 Virtual Time Evolution Method
Basic idea:
let
Denote
We can get an iteration relation
use a set of complementary basis to express the state and the operator
then
Which is known as projection algorithm.
We can also use the Green’s function method
where the third term means that the number of propagators in the propagation process needs to be “renormalized” in a certain way, which can be realized by the process of extinction/replication of propagators in the specific algorithm implementation.
6.6 Stochastic Differential Equation
The most common form of SDEs in the literature is an ordinary differential equation with the right hand side perturbed by a term dependent on a white noise variable.
For example:
- Lorenz-Haken equations
- Langevin equation
- Karkar-porisi-Zhang
- Black-Scholos
6.6.1 Langevin Equation
we have
Ito Lemma:
Then
There’s an extra second-order term here.
where
then
For example:
then
From
we can derive
similarly
If we choose the forward differential, then we have
But if we choose the backward differential and central differential, Then respectively give
We can find that it’s asymmetrical! It illustrates the importance of Ito Lemma.




