Computational Physics (Part1)
Computational Physics (Part1)
[TOC]
1. Interpolation
1.1 Polynomial Interpolation
1.1.1 Lagrange Polynomials
basic ideal: each term
The final formula is:
1.1.2 Barycentric Lagrange Interpolation
motivation: Essentially the same as Lagrange interpolation, but the time complexity is reduced from
define two quantities:
and
The final formula is:
Since we only need to compute
1.1.3 Newton’s Divided Difference
Basic idea: Starting from a sample point, the number of sample points is gradually increased and the interpolation is completed by adding higher order terms without changing the original difference polynomial. At this time, the new coefficient and the original old coefficient satisfy a specific recurrence relationship
Define a function:
It can also be defined recursively by
The final formula is:
Recurrence diagram
1.1.4 Neville Method
Basic idea: It’s also recursion, but in a different way (interpolating recursion from both ends).
The final formula:
1.2 Spline Interpolation
Motivation: Polynomials are not well suited for interpolation over a large range
Basic idea: Often spline functions are superior which are piecewise defined polynomials. After we have chosen the degree of the polynomial, all we need to do is determine the continuity condition.
1.2.1 Cubic Spline
We use third-order polynomials for interpolation
Boundary Conditions:
For
Define
So we can write
And then we can go through the integration, and then we can determine the coefficients based on the boundary conditions.
The final formula:
1.4 Rational Interpolation
1.4.1 Pade Approximant
Basic idea: Using rational function to fit McLaurin series
Which reproduces the McLaurin series of
up to order M+N, i.e.
1.4.2 Barycentric Rational Interpolation
Remark:
it becomes a rational function if we take
and
We can obtain two polynomials
a rational interpolating function is given by
1.5 Multivariate Interpolation
1.5.1 Bilinear Interpolation
It can be written as a two dimensional polynomial
with
1.5.2 Two-Dimensional Spline Interpolation
Basic idea:
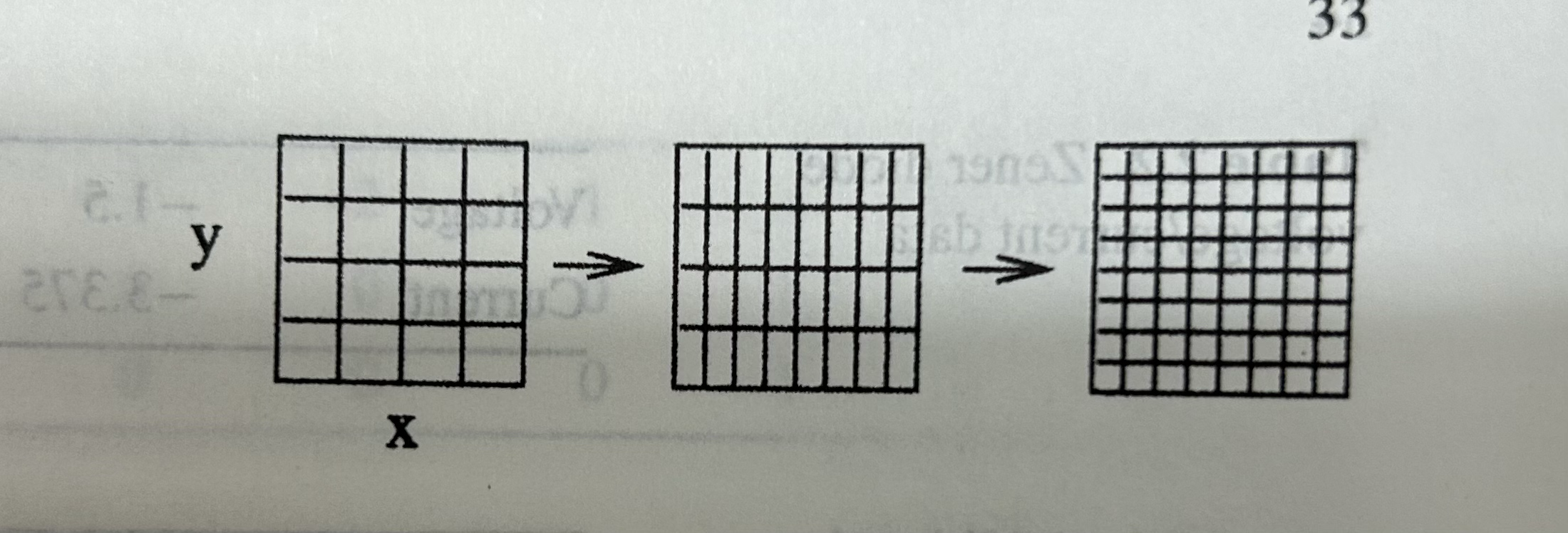
First, for each
Then, for each $i’$, we calculate new data sets of y
1.6 Chebyshev polynomial
the function can be approximated by the trigonometry polynomial with $N=2M,T=2\pi$
Which interpolates
the Fourier coefficient are given by
define
And can be calculated recursively
Hence the Fourier series corresponding to a Chebyshev approximation
2. Numerical Differentiation
2.1 One-Sided Difference Quotient
Forward:
Backward:
truncation error:
2.2 Central Difference Quotient
2.3 Extrapolation Methods
Basic idea: Higher order errors are eliminated by using the low order derivative approximation of asynchronously long lengths, thus achieving higher accuracy (use the method of interpolation)
define:
we choose:
If we want to eliminate the
Using the Lagrange method
Extrapolation for
Neville method
Based on the above interpolation ideas, we can introduce the Neville method,
gives for
2.4 Higher Derivatives
Basic idea: Difference quotients for higher derivatives can be obtained systematically using polynomial interpolation.
Process:
choose
, such as calculate the polynomial using the method of interpolation;
calculate the derivative of the polynomial to obtain the difference quotient we need.
2.5 Partial Derivatives of Multivariate Function
Basic idea: the same as higher derivatives, we can use the polynomial approximation
two-dimension Lagrange interpolation
The interpolating polynomial is
After we obtain the polynomial, we can calculate the partial derivatives of
3. Numerical Integration
In generaal a definite integral can be approximated numerically as the weighted average over a finite number of function values
3.1 Equidistant Sample Points
Basic idea: Equidistant Sample points, just like it’s name said, and plus the interpolation polynomial approximation
Lagrange method
Integration of the polynomial gives
and hence
Using the same method, we can obtain more accurate approximation formula
3.1.1 Closed Newton-Cotes Formula
Larger
Milne-rule
Weddle-rule.
3.1.2 Open Newton-Cotes Formula
Alternatively, the integral can be computed form only interior points
3.1.3 Composite NewTon-Cotes Rules
Basic idea: divided the integration range into small sub-intervals
trapezoidal rule (
Simpson’s rule (
Midpoint rule (
3.1.4 Extrapolation Method (Romberg Integration)
Basic idea: for the trapezoidal rule, we have
we can use
3.2 Optimized Sample Points
Motivation: the polynomial approximation converges slowly, so we should optimize the sample point positions.
Solution: Using orthogonal complete eigenvector expansion to do approximation, improve the convergence speed, and then improve the accuracy of numerical integration
3.2.1 Clenshaw-Curtis Expressions
Basic idea: use the trigonometric polynomial to approximate
Which interpolates
the Fourier coefficient are given by
and can be used to approximate the integral
3.2.2 Gaussian Integration
Goal: we want to optimize the positions of the N quadrature points
General idea: with the help of a set of polynomials which are orthogonal with respect to the scalar product
3.2.2.1 Gauss-Legendre Integration
Basic idea: use the Legendre polynomials to determine the sample point positions in order to approach the
First, we use the Lagrange method
Then
Obviously
Now we choose the positions
Then we have
and
with the weight factors
For a general integration interbal we substituted
The next higher order Gaussian rule can also be calculated easily.
Note: This method is basically the same as the previous equidistant method, the only difference is that the legendre polynomial zero is used as the sampling point.
3.2.2.2 Other Types of Gaussian Integration
We can also use other orthogonal polynomials, for instance
- Chebyshev polynomials
- Hermite polynomials
- Laguerre polynomials
4. Systems of Inhomogeneous Linear Equations
4.1 Gaussian Elimination Method
Basic idea: Gaussian elimination, LU decomposition, two steps
For a matrix
The result has the form
By parity of reasoning,
note that
and
Hence the matrix
which can be used to solve the system of equations
in two steps:
Which can be solved from the top. And
Which can be solved from the bottom
4.1.1 Pivoting
Motivation: to improve numerical stability and to avoid division by zero pivoting is used.
In every step the order of the equations is changed in order to maximize the pivoting element
in the denominator. If the elements of the matrix are of different orders of magnitude, we can select the maximum of
as the pivoting element.
4.1.2 Direct LU Decomposition
have shown above
4.2 QR Decomposition
Where
4.2.1 QR Decomposition by Orthogonalization
Using the Gram-Schmit orthogonalization, we have a simple way to perform a QR decomposition.
where
4.2.2 QR Decomposition by Householder Reflections
Basic idea: use the Householder reflection to eliminate the elements of the matrix A.
Define:
with a unit vector
for a vector
we take
where
then the Householder transformation of the first column vector of A gives
For the k-th row vector below the diagonal of the matrix, we take
Finally an upper triangular matrix results
and
4.3 Linear Equations with Tridiagonal Matrix
Basic idea: for the tridiagonal form, we can easily find the LU matrix, and then we can solve the equations
The coefficient matrix:
LU decomposition
if we choose
since then
and
4.4 Cyclic Tridiagonal Systems
Motivation: Periodic bounday conditions lead to a small perturbation of the tridiagonal matrix
Basic idea: use the Sherman-Morrison formula to reduce this matrix to a tridiagonal system
we decompose the matrix into two parts
then the inverse of the matrix is given by
We choose
Then, the matrix
We solve the system by solving the two tridiagonal systems
and compute
4.5 Iterative Solution of Inhomogeneous Linear Equations
Motivation: Discretized differential equations often lead to systems of equations with large sparse matrices, which have to be solved by iterative methods
4.5.1 General Relaxation Method
Basic idea: decompose the term of
We want to solve
we can divide the matrix
and rewrite (116) as
Which we use to define the iteration
The final formula
4.5.2 Jacobi Method
We choose
which giving
Remark: This method is stable but converges rather slowly.
4.5.3 Gauss-Seidul Method
We choose
the iteration becomes
which can be written as
Remark: This looks very similar to the Jacobi method. But here all changes are make immediately. Convergence is slightly better (roughly a factor of 2) and the numerical effort is reduced.
4.5.4 Damping and Successive Over-Relaxation
Basic idea: convergence can be improved by combining old and new values.
Starting from the iteration
we form a linear combination with
Giving the new iteration equation
Remark:
- It can be shown that the successive over-relaxation method converges only for
. - For optimal choice of
about iterations are needed to reduce the error by a factor of . The order of the method is which is comparable to the most efficient matrix inversion methods.
4.6 Matrix Inversion
Basic idea: From the definition equation of the inverse, we regard
For example, from the definition equation
take the decomposition
or
Condition number
the relative error of
The relative error of




